Entendendo Regressão Linear: as suposições por trás de tudo!
- Laura Damaceno de Almeida |
- Machine learning | Regressão Linear| Introdução |
- 31, Julho de 2020 | 9 mins de leitura
A regressão linear é uma análise que avalia se uma ou mais variáveis preditivas explicam a variável dependente. Os modelos lineares são paramétricos, ou seja fazem algumas suposições sobre os dados que analisa. Quando essas suposições não são atendidas, os resultados de análise de regressão podem ser enganosos e o modelo pode não ter um bom desempenho. Esse artigo vai ser diferente do que eu costumo fazer, pois é um tema que entra em um lado que eu não “manjo” muito, entretanto quando eu vi esse tema no curso que eu estava fazendo, eu achei super importante e pertinente trazer esse assunto, pois é algo que não vemos muito nos artigos escritos em português.
Obs: Antes de seguir a leitura, eu recomendo ler o artigo que eu fiz sobre regressão linear, para entender como é feito a inferência e os cálculos do modelo.
Quais são as premissas?
Precisamos ter em mente as premissas/suposições da regressão linear, caso contrário, o modelo falhará em fornecer bons resultados com os dados. Portanto, para um modelo bem-sucedido, é muito crucial validar essas suposições no conjunto de dados fornecido. Vamos dar uma olhadinha nas premissas:
- O relacionamento entre a variável dependente e independente devem ser linear;
- Não deve haver correlação entre as variáveis independentes;
- Os resíduos devem ter uma distribuição normal;
- Os resíduos devem ter variância constante (homocedasticidade);
- Os resíduos não devem apresentar auto-correlação;
E como identificar se as premissas foram violadas?
1- O relacionamento entre a variável dependente e independente devem ser linear;Uma forma de garantir essa premissa é na hora de fazer o feature engineer, uma alternativa é utilizar o cálculo de Pearson pra calcular a correlação entre os atributos independentes e a variável alvo ou utilizarmos análise gráfica da variável independentes com a alvo para selecionar quais variáveis serão fornecidas como entrada pro modelo.
O interessante da análise gráfica é que conseguimos observar qual o tipo de relacionamento que as variáveis independentes(X) têm e analisar a contribuição da variável delas para Y ou a variável alvo, pois eu quero explicar a variabilidade de Y de acordo com o X.
Se utilizarmos o mesmo exemplo do artigo anterior, prever as notas de matemática (você pode encontrar os códigos utilizados clicando aqui) e plotar as variáveis independente pela dependente, conseguimos obter o seguinte gráfico abaixo, onde podemos notar alguns relacionamentos lineares entre as variáveis NU_NOTA_LC, NU_NOTA_CH e NU_NOTA_CN com a variável alvo NU_NOTA_MT.

Vale lembrar que o cálculo de Pearson retorna um valor entre 1 e -1, e quanto mais próximo de 1 há uma relação linear forte positiva, já próximo de -1 há uma relação linear forte negativa e mais próximo de 0 não relacionamento linear entre as variáveis.
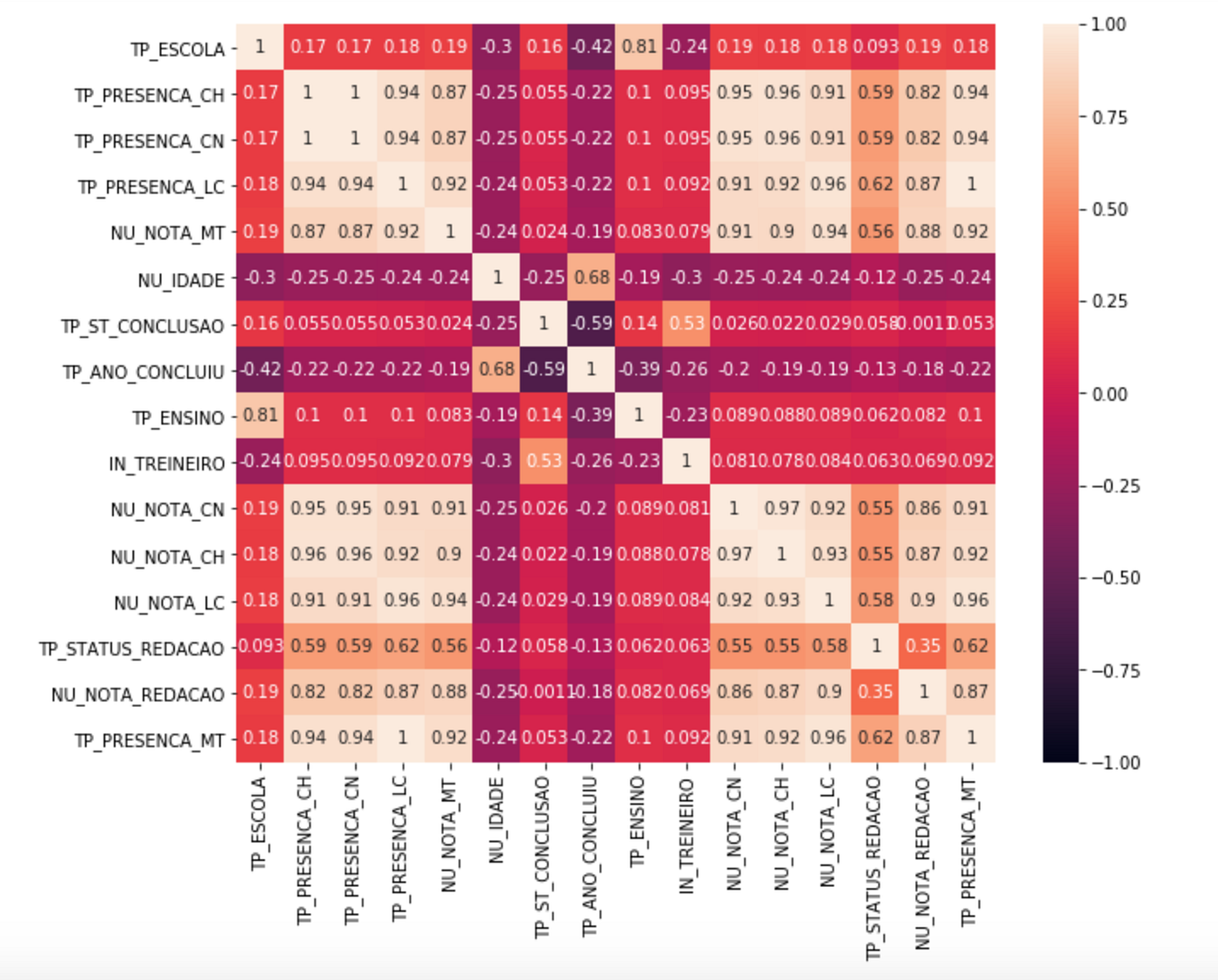
2- Não deve haver correlação entre as variáveis independentes (multicolinearidade)
Quando as variáveis independentes são correlacionadas entre si, temos um problema chamado multicolinearidade.
Isso leva ao desenvolvimento de um modelo com coeficientes que possuem valores que dependem da presença de outras variáveis. Em outras palavras, teremos um modelo que mudará drasticamente se uma variável independente for removida, portanto um modelo como esse será impreciso.
Então na hora de selecionar as variáveis independentes, escolhas as que tem uma correlação alta com a variável alvo e que não tenham correlação com outras variáveis independentes ou que tenham uma correlação muito fraca.
Vamos para um exemplo: Conforme o exemplo que eu utilizei no artigo sobre regressão linear, a variável independente utilizada é a Nota de matemática (NU_NOTA_MT) e se notarmos ela tem uma correlação alta com outras variáveis, agora se olharmos para uma dessas variáveis por exemplo: TP_PRESENCA_CH, que é se o aluno foi ou não na prova de ciências humanas, ela tem uma correlação alta com outras variáveis, por exemplo: TP_PRESENCA_MT, NU_NOTA_CN, NU_NOTA_CH, etc..
Portanto vale refletir se essa variável é realmente importante pro modelo, se for, precisamos levar em consideração a correlação da variáveis TP_PRESENCA_MT, NU_NOTA_CN, NU_NOTA_CH com a variável alvo e escolher dentre elas e a TP_PRESENCA_CH qual melhor se ajusta ao modelo.
3- Os resíduos devem ter uma distribuição normal
Isso é feito para que o erro padrão das estimativas sejam calculados corretamente.
Mas o que são resíduos?Conforme o conceito explicado no meu artigo sobre regressão linear, O resíduo representa a quantidade da variabilidade que Y que o modelo ajustado não consegue explicar. E os resíduos podem ser calculados com a seguinte fórmula:
residuo = Y-Yˆ
Onde Y é o valor real e Y^é o valor calculado pelo modelo.
Para verificar se seus resíduos apresentam uma distribuição normal, você pode usar gráficos: histograma, X ou Q-Qplot.
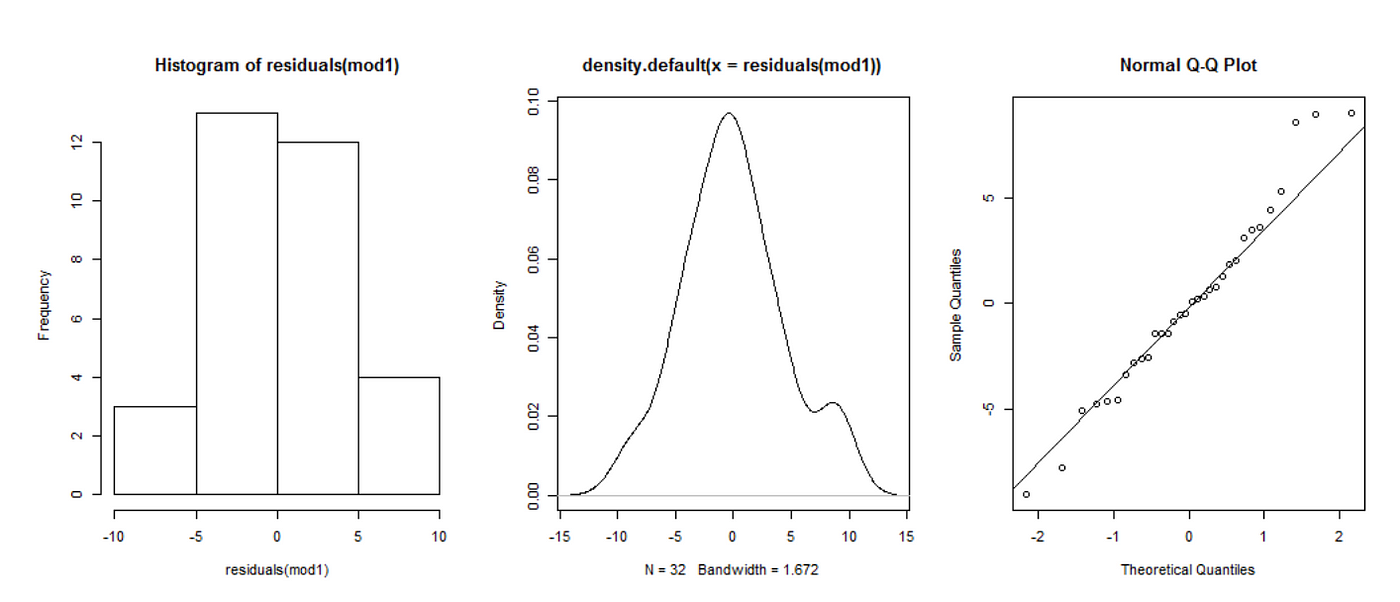
Ou realizar o teste de Shapiro-Wilk, que também mostra se existe normalidade dos resíduos, retornando o valor de p-value:
- Se o p-valor for maior que 0,05 => resíduos com normalidade
- Se o p-valor for menor que 0,05 =>resíduos sem normalidade
4- Os resíduos devem ter variância constante (homocedasticidade)
Com a regressão é assumido que cada ponto de dados contribui com explicação igual para a variabilidade que estamos procurando modelar. Se alguns pontos de dados contribuíram com mais explicação que outros, nossa linha de regressão será puxado em direção aos pontos com mais informação.
Homocedasticidade é o termo para designar variância constante dos erros/ resíduos para observações distintas (Xij). Caso a suposição de homocedasticidade não seja válida, podemos dizer que:
- Os erros padrões dos estimadores, obtidos pelo Método dos Mínimos Quadrados, são incorretos e portanto a inferência estatística não é válida.
- Não podemos mais dizer que os Estimadores de Mínimos Quadrados são os melhores estimadores de mínima variância para β.
Quando não há variação constante, temos o problema de heterocedasticidade, ou seja, a variância dos erros será diferente para cada valor condicional de X. Podemos observar se há esse problema de 2 formas: Análise gráfica, ou Testes estatísticos.
Através da análise gráfica podemos utilizar a imagem a seguir.

Já com os testes estatísticos pode ser utilizado: Teste Goldfeld-Quandt, Teste de Breusch-Pagan , Teste de White. Não irei entrar em detalhes sobre o que seria cada um destes testes e como utilizá-los, entretanto deixarei alguns links pra caso vocês tenham interesse no assunto.
5- Os resíduos não devem apresentar auto-correlação
Esta premissa pode ser verificada graficamente, representando os resíduos em função dos valores estimados da variável dependente Y, em um gráfico residual.
Quando há correlação nos resíduos, temos o problema conhecido como auto-correlação. A existência dela é uma violação grave das premissas do modelo linear, pois interfere diretamente na distribuição dos resíduos.
Modelos que apresentam auto-correlação nos resíduos são claramente identificados através da análise de resíduos, podendo ser identificado quando os resíduos não se comportam de forma aleatória, ou seja, seguem um padrão, e demonstram uma falha grave na especificação do modelo para o conjunto de dados.
Além da visualização gráfico, você pode validar se há auto-correlação nos resíduos, utilizando o teste estatístico chamado Durbin-Watson, que testa a hipótese nula de que os resíduos não são linearmente correlacionados automaticamente, o resultado final varia entre 0 e 4, e valores entre "1,5 < d < 2,5" mostram que não há correlação.
Para quem quiser realizar as validações das premissas nos dados, tem esse artigo que o autor realizou essas validações no python , e para os apaixonados por R tem um artigo sensacional escrito pela comunidade da linguagem, para acessar clique aqui.
Ufa!! Muita informação né?! Então nesse artigo aprendemos:
- 1- O que é uma premissa e qual a sua importância nos nossos modelos de regressão linear.
- 2- Quais são essas premissas.
- 3- Quais explorações ou testes estatísticos fazer para garantir que as premissas não estão sendo violadas.
Share love

Sobre a autora
Pyladie de coração e cientista de dados na IBM, apaixonada por IA e ciência de dados. Acredita que ambas tecnologias podem causar um impacto positivo na sociedade.
Veja mais