Gerando wordcloud com os tweets sobre a série “Anne with an E”
- Laura Damaceno de Almeida |
- NLP |Text mining |
- 13, Fevereiro de 2020 | 7 mins de leitura
“Nós, mulheres, poderosas e sagradas, declaramos nesta noite santificada que nossos corpos divinos pertencem a nós mesmas. Escolheremos a quem amar e em quem confiar. Caminharemos nesta Terra com graça e respeito. Sempre teremos orgulho do nosso grande intelecto. Honraremos nossas emoções para que nossos espíritos triunfem. E se algum homem nos desmerecer, mostraremos onde fica a porta. Indestrutível é a nossa força. E livre é a nossa imaginação.” (Anne with an E)
Já vamos iniciar com essa frase SENSACIONAL dita pela personagem mais incrivel de todos os tempos: a Anne,a série vem ganhando cada vez mais espaço na mídia por falar de assuntos importantes de uma forma sensível e sutil, como por exemplo: racismo, feminismo e auto aceitação, além de nos fazer refletir sobre como as simples coisas do mundo podem ser magníficas e que com imaginação e bondade, podemos passar por todas a situações da vida.
Mas antes de partimos pra mão na massa, precisamos entender alguns conceitos básicos. (então segura a emoção um pouquinho!).
O que é NLP (Natural Language Processing)?
NLP ou Linguagem de processamento natural é um ramo da inteligência artificial que se dedica a entender a relação da linguagem humana (falada, escrita) e a linguagem de máquina. E eu resolvi fazer um wordcloud ou uma nuvem de palavras com os tweets dos usuários sobre a série “Anne with an E”. P.S: Eu disponibilizei os códigos usados nesse artigo no meu repositório do Github.
O que é um wordcloud?

Wordcloud ou nuvem de palavras é muito utilizada na exploração dos textos, para entender melhor quais palavras são frequentes nas frases, e assim realizar os possíveis tratamentos nelas ou entender melhor por exemplo: o que seus usuários ou clientes estão comentando sobre um determinado produto ou empresa.
Vantagens de utilizar wordcloud nas análises
Podemos analisar milhares de feedbacks de texto e com ele levantar os termos mais citados , que nos ajudam a entender:
- Pontos de sua marca que encantam clientes;
- Itens que não atendem as necessidades do seu público;
- Relacionamentos problemáticos durante a jornada de compras;
E com tudo isso teremos os tópicos mais importantes referentes ao negócio e priorizar quais deles são mais importantes de priorizar, ou seja, tomamos decisões mais assertivas.
Extração dos tweets:
Para extrair tweets do Twitter você precisa ter uma conta no Twitter developer instalar a biblioteca TwitterSearch , com ela podemos conectar com a API do Twitter para realizar essa extração. (vou deixar no final desse artigo a recomendação de um artigo excelente para a geração da API Key e os tokens)
def generate_tweet(key,secret,token,token_secret, pesquisa_tweet, language):
try:
tweets = TwitterSearch(
consumer_key = key,
consumer_secret = secret,
access_token = token,
access_token_secret = token_secret
)
pesquisa = TwitterSearchOrder()
pesquisa.set_keywords([pesquisa_tweet])
pesquisa.set_language(language)
tweetss = []
for tweet in tweets.search_tweets_iterable(pesquisa):
tweetss.append(tweet)
with open('tweets.json', 'w') as arq:
json.dump(tweetss, arq, indent=2)
except TwitterSearchException as e:
print(e)
Para fazer um filtro sobre um determinado assunto, usamos o método “.set_keywords()” e podemos filtrar a língua dos tweets com o método “.set_language()” Neste meu método eu crio um arquivo chamado “tweets.json” para armazenar todos esses tweets que eu filtrei, onde eu carrego ele no meu notebook transformando-o em um Dataframe para ficar mais fácil a manipulação.
Pré-processamento:
É bem importante fazermos os pré processamentos nos tweets, pois grande parte deles vai vir com “stop words” ou palavras consideradas irrelevantes para o nosso processamento (preposição, artigos e pronomes),podemos remover os acentos nas palavras, espaços a mais e por aí vai. Ou seja, neste pré-processamento nós transformamos esses dados não estruturados em estruturados e em representações multi-dimensionais.
Por exemplo a frase:
O Batman é melhor que o supermanApós esse pré-processamento teremos:
Batman melhor SupermanOu seja nosso modelo de NLP ou nossas análises vão poder focar nas palavras que realmente são importantes para o negócio. Para isso eu criei um método para a remoção de acentos, números e espaços.
Para isso eu criei um método para a remoção de acentos, números e espaços.
def removerAcentosECaracteresEspeciais(frase):
frase_sem_acento = unidecode.unidecode(frase) #remove acentos
# Usa expressão regular para retornar a palavra apenas com números, letras e espaço
return re.sub('[^a-zA-Z0-9 \\\]', '', frase_sem_acento)
Stop words pode afetar no nosso wordcloud pois esse tipo de visualização pega quais frases são mais frequentes dentre todas e com certeza as palavras “e, com, que, o” são bem frequentes. Neste método eu estou gerando tokens nas frases para que possa facilitar a stop words e algumas pontuações (‘,’’.’, ’#’, etc..).
frase_processada = list()
def tokenize_frase(frase):
palavras_texto = frase.lower()
palavras_texto = token_pontuacao.tokenize(frase)
palavra = []
stopwords = nltk.corpus.stopwords.words('portuguese')
for i in palavras_texto:
if not i.isnumeric() and i.lower() not in stopwords and i not in pontuacao:
palavra.append(i.lower())
frase_processada.append(' '.join(palavra))
def preprocess(data):
data = removerAcentosECaracteresEspeciais(data)
tokenize_frase(data)
Gerando o wordcloud
Para gerar o Wordcloud precisamos passar uma lista de palavras, portanto eu gerei uma lista partir das nossas frases pré processadas chamada “todas_palavras”.
Para gerar um wordcloud precisamos instanciar esse objeto “WordCloud( )” e depois usamos o comando “.generate()” para gerar esse wordcloud. Portanto nosso código ficaria assim: word_cloud = WordCloud( ).generate(todas_palavras)
Para exibir essa nuvem de palavras usamos os seguintes comandos: plt.imshow(word_cloud, interpolation=”bilinear”) plt.show() . Eu criei um método para que possamos reutilizar nosso wordcloud de uma forma mais fácil, mas você pode optar por não utilizar métodos.
def wordcloud_tweets(texto, coluna_texto):
todas_palavras = ' '.join([texto for texto in texto[coluna_texto]]) #lista contendo todas as frases
word_cloud = WordCloud(width=800, height=500,max_font_size=110).generate(todas_palavras)
plt.figure(figsize=[10,10])
plt.imshow(word_cloud, interpolation="bilinear")
plt.title('Wordcloud dos tweets sobre a série Anne with an E')
plt.axis("off")
plt.show()
wordcloud_tweets(tweets_filme,'tratamento_1')
E o seu resultado deve ser parecido com este:
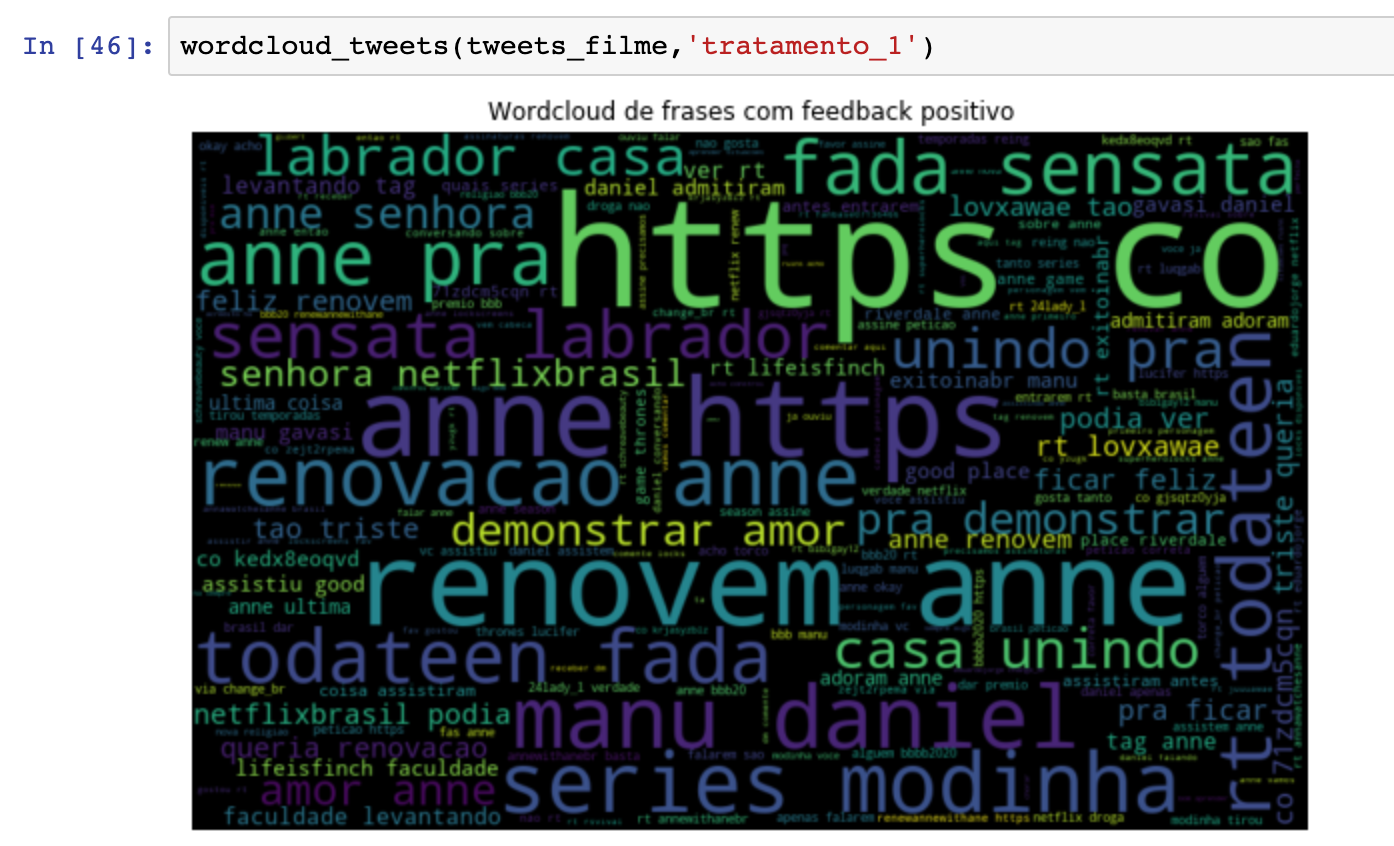
Antes de finalizar, vale ressaltar que o wordcloud é uma excelente ferramenta de visualização que facilita a análise dos textos ou text analysis, permitindo a visualização da distribuição de frequência das palavras e assim podemos melhorar o nosso pré processamento ou o entendimento dos nossos usuários. E para acessarem o artigo que ensina a gerar os tokens, clique aqui.
E por isso é tudo pessoal!!

Aproveita e me segue nas redes sociais para companhar mais de perto os meus trabalhos ;), no Linkedin e Instagram
Share love

Sobre a autora
Pyladie de coração e cientista de dados na IBM, apaixonada por IA e ciência de dados. Acredita que ambas tecnologias podem causar um impacto positivo na sociedade.
Veja mais